The x86 Killer? Why NVIDIA’s “Vera” CPUs Could Outrun Intel and AMD at Computex
For years, the computing industry has operated under a strict dichotomy: NVIDIA built the GPUs that accelerated the future, while Intel and AMD built the x86 CPUs that orchestrated everything else. But as we approach Computex 2026 in Taipei, the lines separating those domains are being violently erased.
According to explosive reports from financial analysts at GF Securities, NVIDIA is preparing to use its June 1st Computex keynote to directly attack the x86 duopoly. At the center of this offensive is “Vera,” NVIDIA’s second-generation Arm-based CPU. Purpose-built for the rapidly expanding era of “Agentic AI,” NVIDIA is reportedly preparing to market Vera as a definitive x86 killer in the data center.
With Ian Buck (NVIDIA’s VP of Hyperscale) already hand-delivering the first Vera systems to industry titans like OpenAI, Anthropic, and SpaceX this past week, the hype is reaching a fever pitch. Here is the comprehensive, deep-dive breakdown into why NVIDIA’s Vera CPU has the potential to completely outrun Intel and AMD’s best silicon at Computex 2026, and what it means for the future of server architectures.
The Computex 2026 Showdown: The 1.5x Performance Claim
When Jensen Huang takes the stage in Taipei, he is not just going to talk about GPUs. According to the GF Securities report, NVIDIA will dedicate a massive portion of its presentation to undermining traditional x86 server dominance.
The Analyst Predictions
The 1.5x Metric: NVIDIA is expected to boldly claim that the Vera CPU delivers 1.5x faster speeds and 2x the overall efficiency compared to the absolute best x86 alternatives currently available from Intel and AMD.
Density Dominance: In the data center, physical space is just as valuable as compute power. NVIDIA will reportedly showcase that Vera-based server racks offer a staggering 4x higher density per rack than traditional dual-socket x86 deployments, fundamentally changing the real estate math for cloud providers.
The Computex Contrast: While NVIDIA focuses its Computex narrative on dominating the high-margin “AI Factory” host processor market, analysts expect Intel to spend its stage time largely on the defensive, focusing on its entry-level “Wildcat Lake” consumer chips to combat Apple’s MacBook Neo. This sharp contrast in messaging will heavily reinforce NVIDIA’s position as the undisputed leader of high-end compute.
The True Total Addressable Market (TAM)
The AI Expansion: Why does NVIDIA care about CPUs suddenly? Because Agentic AI is expanding the Total Addressable Market for server processors. Analysts predict that as autonomous AI agents take over 30% of inference workloads, the CPU TAM will explode to $211 billion by 2030. NVIDIA wants to capture that massive revenue stream instead of letting it default to AMD’s EPYC or Intel’s Xeon lineups.
Unpacking the Vera Architecture: The “Olympus” Core
To claim you can outrun the x86 giants, you need fundamentally superior architecture. NVIDIA didn’t just iterate on their previous Grace CPU; they completely redesigned the silicon from the ground up for specific workloads.
A Shift from Brute Force to Core Capability
The 88-Core Layout: AMD’s upcoming Zen 6 “Venice” architecture relies on massive core density, scaling up to an absurd 256 cores per socket. Intel’s Xeon 6980P pushes 128 cores. NVIDIA’s Vera CPU, surprisingly, packs a much more modest 88 custom Arm v9 cores, codenamed “Olympus.”
NVIDIA Spatial Multithreading (SMT): Instead of standard time-slicing hyper-threading used by Intel and AMD, Vera utilizes a proprietary Spatial Multithreading approach. This physically partitions the resources of each Olympus core at runtime, yielding 176 total hardware threads that can dynamically optimize for either raw performance or extreme density depending on the immediate workload.
Native FP8 Precision: Vera makes history as the first general-purpose CPU to support FP8 precision natively in the instruction set architecture (ISA). While it doesn’t replace a GPU tensor core, this allows the CPU to rapidly handle lightweight AI tasks—like quantized embeddings and small policy filters—without ever needing to wake up a power-hungry GPU.
The Memory Bandwidth War: Breaking the Bottleneck
The secret weapon of the Vera CPU, and the primary reason it can claim a 1.5x performance victory over chips with triple the core count, lies entirely in its memory subsystem. In 2026, compute isn’t constrained by logic gates; it is constrained by the memory wall.
The SOCAMM Advantage
Bypassing Traditional DDR5: Top-tier x86 chips from Intel and AMD are tethered to traditional DDR5 server platforms. Even with massive 12-channel setups, they peak at roughly 600 GB/s to 800 GB/s of bandwidth. NVIDIA threw out the traditional server motherboard blueprint entirely.
1.2 TB/s of Throughput: Vera utilizes a 1,024-bit LPDDR5X interface spread across eight proprietary SOCAMM memory modules. This customized layout delivers a mind-bending 1.2 Terabytes per second (TB/s) of memory bandwidth, with support for up to 1.5 TB of total capacity per socket.
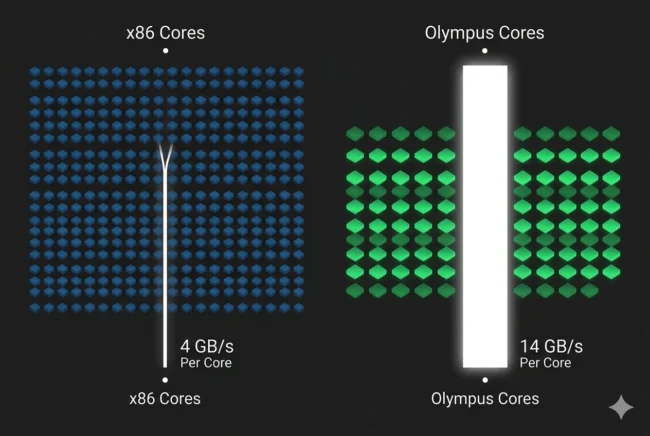
The Per-Core Math That Terrifies x86
Starving the Cores: When you divide AMD’s 614 GB/s of bandwidth across its massive 192 cores (EPYC 9965), each core is only fed roughly 3.2 GB/s to 4.8 GB/s of data. If the workload is heavily memory-bound, those incredible Zen cores sit idle, waiting for data.
Vera’s Unrestricted Flow: Because Vera has fewer cores but vastly more total bandwidth, it delivers an astonishing 14 GB/s of bandwidth per core. This 3x to 4x per-core bandwidth advantage ensures that in Extract-Transform-Load (ETL) operations, real-time analytics, and massive database queries, Vera maintains 100% throughput while x86 chips choke on their own traffic.
The Rise of “Agentic AI”: Why the CPU Matters Again
To understand why NVIDIA built Vera, you must understand the massive shift occurring in software development right now. The industry is moving from standard generative AI to Agentic AI.
The GPU Orchestration Problem
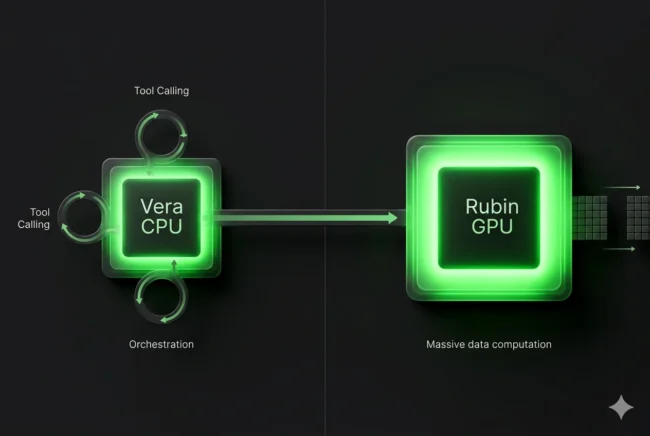
Moving from Answering to Acting: Traditional Large Language Models (LLMs) take a prompt and generate a text answer. GPUs are fantastic at this parallelized math. But an AI “Agent” is different. An agent takes a prompt, formulates a multi-step plan, opens a web browser, runs a Python code interpreter, queries a SQL database, and validates the results.
The Sequential Nightmare: Tool-calling, operating system orchestration, and sandboxing are highly sequential, latency-sensitive tasks. If you try to run these on a Rubin GPU, it is horribly inefficient. The massive GPU sits there, burning immense amounts of power, waiting for a web browser to load or code to compile.
The Ultimate AI Host
The Reinforcement Learning Sandbox: Vera is purpose-built to handle these complex, sequential agent sandboxes. By offloading the orchestration, context retrieval, and tool execution to the 88 ultra-fast Olympus cores, the expensive Rubin GPUs are kept 100% utilized on pure matrix math.
Second-Gen SCF: Vera’s second-generation Scalable Coherency Fabric (SCF) provides a 3.4 TB/s on-chip mesh, ensuring that as thousands of AI agents run in parallel software environments, the latency between the CPU, the shared L3 cache, and the GPUs remains perfectly deterministic.
Early Adoption: The Heavy Hitters Are Already Onboard
NVIDIA is not waiting for Computex to prove Vera’s viability; they are aggressively seeding the market with production silicon to secure architectural lock-in before AMD and Intel can mount a defense.
Hand-Delivering the Future
The Silicon Valley Tour: Last week, Ian Buck, NVIDIA’s VP of Hyperscale, personally hand-delivered the first production Vera systems to the absolute elite of the AI world. Stops included Anthropic in San Francisco, OpenAI in Mission Bay, and a highly publicized meeting with Elon Musk at SpaceX’s xAI offices in Palo Alto, where the system will be evaluated for massive reinforcement learning pipelines.
Oracle’s Massive Bet: The most alarming news for Intel and AMD is the commitment from Oracle Cloud Infrastructure (OCI). Oracle has already publicly confirmed plans to deploy hundreds of thousands of NVIDIA Vera CPUs beginning in the second half of 2026.
The Revenue Shift: Oracle recognizes that traditional x86 server infrastructure cannot provide the density required to offer production-grade Agentic AI to enterprise customers at scale. By committing to Vera, Oracle is effectively diverting billions of dollars in hardware procurement away from Team Red and Team Blue directly into Jensen Huang’s pockets.
The Verdict: Different Tools for Different Wars
Is the NVIDIA Vera CPU truly an “x86 killer”? If you are looking at raw, generalized enterprise data center tasks—like running legacy corporate virtual machines, standard web hosting, or basic cloud instances—the answer is no. AMD’s Zen 6 “Venice” and Intel’s Diamond Rapids will continue to dominate traditional server racks through sheer core volume and established x86 software compatibility.
However, the future of high-margin computing is not in legacy web hosting; it is in the “AI Factory.” In the realm of Agentic AI, reinforcement learning, and massive data pipelines, core count is meaningless without bandwidth. By prioritizing memory throughput, customized agent-focused silicon, and tight NVLink integration with their own GPUs, NVIDIA has engineered a CPU that makes x86 look archaic in the workloads that matter most to Silicon Valley right now.
When Computex 2026 kicks off, expect Intel and AMD to show off impressive, massive CPUs. But expect NVIDIA to show the world that the rules of server performance have fundamentally changed, and they are the only ones holding the new blueprint.